中国开云 吐槽一下, 找外包采了几百条数据, 能用的剩下一百条!


头图:具身智能行业图片
各人好,我是瓦力,具身算法筹商员。
先说个事情。前一阵咱们找外包采了一批遥操数据,三百多条。终末能进查考集的,一百条出面。剩下的两百条数据,有手脚彷徨、结尾定位偏差、要道帧被遮盖的。一条条看数据,的确挺熬东说念主。经过都对,东说念主也到位,钱也花了,扫尾一泰半的数据都没办法用。
我深信这亦然大部分作念算法的推行感受。模子调到一定进度,瓶颈基本都不在模子本人,是喂进去的数据。何况这个问题还不是费钱堆量就能解决的。你跟外包把需求讲了半天,对方点头说懂了,采出来的东西讲解注解根柢没懂。
卡到自后,我启动四处问东说念主,有莫得靠谱的办法能把数采作念塌实点。问了身边搞具身的同学,发现各人遭遇的问题大差不差,然后有个一又友给我指了条路,说不错问问数采厂。
我一启动是不深信的。数采厂嘛,无外乎把经过作念圭表、把东说念阁下好。外包的东说念主也大多是他们提供。骨子厂商和标注公司我也战役过,大同小异。
抱着取经的作风,我如故问了下之前天南战役过的几家公司。聊完之后,我才发现我方想的有些窄了。他们想干的,不只单是把辘集经过优化得更好。有些公司致使想作念更大的事情,把数据和模子这两件事,融在一王人。
这家厂是乐聚,我差未几从他们那里找到了一些有道理的想路,是以和各人共享一下know how。
1. 采数据这件事,外包只可处置一半
先把问题说了了。
目下行业里采数据,大多数是两拨东说念主。一拨在查考端,懂模子、懂算法,知说念一条好数据长什么样;另一拨在辘集端,可能是外包,也可能是数据标注公司,追究遥操或者无骨子的数采。
这两拨东说念主之间,其实不太意会对方。
查考端的东说念主,常常不会躬行去采几百小时。辘集端的东说念主,又基本碰不到模子查考。扫尾即是,需求在传递的过程中一层层失真。
比如我想告诉外包的同学说「我想要这个持取的战役一霎稳极少」,传到辘集端可能就酿成了「很慢的把东西持起来」。这中间丢掉的信息,其实即是我想要模子学习的东西。
所除外包能处置的,其实只好一半:量。它能给你堆出几百上千小时的数据。但另一半,质,或者说跟模子需求的对王人,它给不了太多。
这让我想起之前写许华哲那篇时,Pete 抛过的一个问题:全世界的机器东说念主学家,该不该放下筹商一年,挑升去辘集数据。
那时我的判断是不可真这样干,但如实值得算法的同学试一试。是以我也的确去试了试,就在乐聚那儿。
我那时通过遥操把天平上的砝码放到盒子里的时刻,我对了好一会儿才把最大的砝码放进去。但从数据本人的角度,或者从东说念主类的角度,我以为应该很班师能放进去才对。
但你说数采员能作念的更好么,我以为也不大可能了。
推行体验下来,我最大的感受之一即是:目下其实不是没东说念主采数据,是采转头的数据,和算法想要的还有很大的距离。
想要把数据作念成工业品,前提是采的东说念主得懂模子,懂模子的东说念主也得知说念辘集推行的景色。不然你经过作念得再行为,采的东西不一定是模子需要的。
这即是为什么我说,外包只可处置一半。不是外包不起劲,是这套单干从结构上就注定了数据质料的天花板。
2. 数据和模子分不开,我以为有两层含义
聊到这,得说回乐聚让我以为有道理的处所。
许多东说念主讲「数据和模子分不开」,聊的都是名义:你得额外据才气训模子。这层太浅了,谁都懂。我以为确切的分不开,是两层。
第一层是硬件层。你得的确用过各家的骨子,才知说念不同构型的骨子在采数据时会踩什么坑。轮臂的坑、双足的坑、不同奢睿手的坑,都不一样。 一个只作念自家骨子的厂商,数据重点可能只会 focus 在自家居品上,他莫得能源、也莫得场景去试水别家骨子的坑。乐聚参与建立寰球多个东说念主形查科场,他们骨子的数目多,数采需求大。本人就在采全身运控、奢睿手操作、轮臂基础运控这些不同构型的数据,它对跨骨子的底层互异,意会是更全的。
第二层是组织层,这点更庞杂。采数据的东说念主,必须懂算法要什么。前边说的问题,2026世界杯官方指定中国区认证平台外包搞不定,骨子厂商其实也隔着半说念墙,因为模子团队和数据团队往往是两拨东说念主、两个 KPI。
而乐聚此次干的事,是把数据工场和后查考算法库,作念到了一王人。辘集端和查考端,是归并拨东说念主在对王人需求。采数据的时刻,脑子里装着的即是模子要什么。
这两层叠在一王人,才是完满的「数据和模子分不开」。我知说念这里有东说念主要反问:乐聚我方不亦然骨子厂吗?夸父即是它的机器东说念主,凭什么说骨子厂不行,它就行?
这个问题问得很对,我我方的第一反应亦然这样。
但我周末在他们线下体验完,能嗅觉取得乐聚正在从一个「卖骨子」的公司,转向作念 infra,现阶段在作念的即是「辘集和捕快对王人」。
三月份天南和各人聊乐聚,就在说他们也要作念的具身基座,我体验完之后守旧这个见解。
是以他们此次发布的后查考系统,我以为是沿着这个标的再鼓吹。
3. 四款骨子里,唯独跑通闭环的是双足
这套后查考系统主若是乐聚我方作念的,测试用的 LingBot-VLA预查考灵验到乐聚的真机数据。
确切让我感酷好的不是这个,是他们怎么去讲解注解这套后查考系统。乐聚没只秀「我的骨子跑通我的模子」,他们搭了两个标的的对照。
横进取,以夸父 KUAVO 4 Pro 这台骨子,去适配 5 个主流模子,看哪个进展最佳。纵进取,拿 LingBot-VLA 这一个模子,放到 4 款不同骨子上去跑,看各家骨子的适配情况。
这种横纵交叉的蓄意,是会透露站位的。
一个纯骨子厂,只会秀「我的骨子加我配合的模子,精通活」。一个纯模子厂,只会秀「我的模子,在常见骨子上能跑」。
只好一个把我方定位成中间层、定位成后查考这一层的玩家,才会良友去作念这种横纵交叉的对照。因为只好站在中间,这两个标的才都是你的业务。
更有道理的是纵向的扫尾,参与的 4 款骨子里,夸父是唯独的双足东说念主形,何况它把整条闭环跑通了。双足是很难的骨子,这个无谓我多说。轮臂、机械臂底盘稳、手脚空间规整,双足光是站着不晃就仍是在阔绰一堆适度余量。
把我方难啃的双足,中国开云放到蚂蚁的模子下面去跑。
我的解读是,乐聚这是把赌注摆明了:模子是谁的不庞杂,骨子是不是最难的也不庞杂,他们押的是中间这套从真机数据到失败归因的闭环,能不可把难的组合跑通。
虽然,这个手脚若干是作念给各人看的,咱们暂且不论。但双足这关真跑通了,至少讲解这套闭环能 work。
这条闭环,买通的是 真实机数据 → 模子后查考 → 多骨子部署 → 真实机评测 → 失败归因回流。它 solid 的不是某一段,是「回流」两个字,失败的案例能自动喂且归驱动下一轮迭代。
开云体育·(KAIYUN SPORTS)官方网站站位,即是这样用一个手脚摆出来的。
4. 平均不到20%的收服从,我有些疑问
再聊点现实。
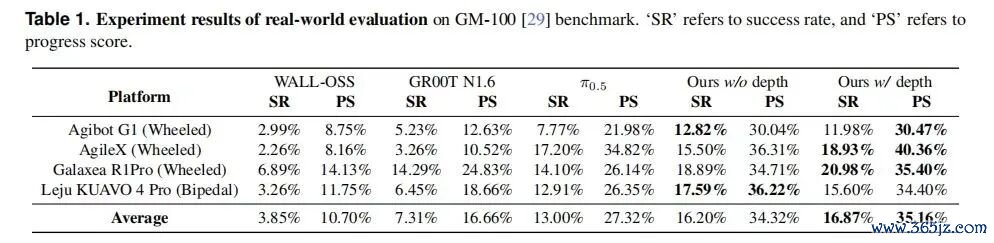
乐聚后查考在 95 个场景的横向测评里,平均收服从(SR)是 17.59%,平均过程得分(PS)是 36.22%。坦率讲,17.59% 的扫尾,有点低。我的第一反应即是:这到底是数据不行,如故模子不行?
这个问题我也平直问了乐聚的追究东说念主,他们跟我解释的随机道理如下:
第一,任务是的确难。这 95 个场景里,许多不是单步持放,而是良好插入、器用使用、擦抹隐蔽、小主见按压、动态战役、贯通搬运、多阶段状态养息。这些任务你换成东说念主手去作念,都得屏住呼吸。
我现场拍的测试过程,好远离易收效的一条。

第二,真机践诺难。归并个模子,换一台机器东说念主,骨子结构、结尾夹爪、相机视角、手脚空间、适度频率全变,扫尾随着变。这恰好反证了前边说的,跨骨子有多难。
第三,SR 体现的并不完满。SR 只看终末有莫得完满作念完,中间任何一步崩了就算 0 分。而 PS 过程分才反应过程鼓吹到了哪一步。复杂的多阶段任务,只盯着 SR 是不自制的,GM-100 论文也挑升说了这点,是以才另外界说了算计子任务完成度的主见。也即是说,PS 的 36.22% 比 SR 更能讲解模子真实的才气。
第四,它考的是长尾泛化,不是牵挂。LingBot-VLA 论文里提到,测试聚会不祥 50% 的手脚,根柢不在查考集前 100 高频手脚里。等于挑升挑模子没怎么见过的组合来考,考的是举一反三,不是背谜底。
讲到这,得直面一个问题,我我方一启动亦然这样问的:就 150 条数据查考,会不会仅仅为了考据一下经过跑得通,拿来比收服从有点站不住脚? 乐聚的同学跟我强调,他们不是松弛的经过考据,是小样本条目下的压力测试,外加一次长入预算的横向相比。
给总共模子相似 150 条的后查考预算,自制地比谁泛化得更好。在这个长入预算下,LingBot-VLA 的两容貌标都是最优,PS 比强基线 π0.5 当先近 10 个点。
这个解释倒能说得通,不外倒也算是揭了真机使命的遮羞布。
总共这个词行业距离可靠的通用操作,差距还很大啊。
乐聚顺遂还作念了垂直场景的落地。相似这套系统,到了具体的场景,比如汽车制造里的料箱拆垛,轮廓收服从作念到了 95% 以上,手段扫尾从最初的 30% 出面,提到了 80% 到 90%。
一个是通才压力测试上的 17.59%,一个是专才落地场景里的 95%。这两个数不矛盾,它恰正是「通才变专才」这条路的字据。
而把通才逼成专才的,即是中间那套后查考系统。
5. 把通才逼成专才的,是中间那套系统
这套系统的中枢,是一个自研的后查考算法库。细节我不逐个伸开,Github上仍是开源了。
挑两个我以为相比实在的,用东说念主话讲一下。
一个是针对「横祸性渐忘」的。
VLA 基模微调有个老差错:外行段学会了,预查考阶段的本钱事却丢了。乐聚用的是基于 LoRA 的轻量微调,你不错意会成,给模子注入外行段的时刻,尽量别去动它本来那套广宽的先验,这样它濒临没见过的物体,泛化才气才不会塌。
另一个是交融了生成式世界模子的后查考。
传统 VLA 许多时刻是在机械地师法示范手脚,并不睬出恭脚背后的物理因果。加了世界模子之后,相称于让模子动手之前,先在脑子里预演一下「我这样操作,接下来会发生什么」,再据此选当下合理的手脚。说东说念主话即是,从背谜底,酿成了边推理边干。
算法库之外,是三条器用链:数据辘集处理平台、后查考器用链、端侧部署测评器用链。
串起来,即是一条从数据到现场的完满活水线。其中阿谁数据平台很戳我,它把行为化的数据清洗作念成了活水线,采完平直输出干净数据,传闻能把本来 3 到 5 天的清洗工时压到一天。
开源的代码库我周末也用他们数据跑了一下,没什么很大的坑。
这套东西成不熟谙,还有个侧面的字据:在刚已毕的 ICRA 2026 的 REAL-I 挑战赛里,全球高校的学生,依托乐聚盛开的数据集和全栈器用链,一天之内就能从零起步,把模子部署到真机上,跑通金属件翻正、日化瓶取放、快递包裹扫描这三个真实工业场景。
学生一天,从零到真机跑通。
能把上手门槛压到这个进度,讲解这套后查考系统,如实在往「工业品」的标的作念。
写在背面
回到最启动。我之是以去找乐聚,是因为我我方的数据采得不顺,外包采转头一泰半不可用,根子在于采的东说念主不懂模子需求。
是以乐聚继承我方买通数据和模子,我以为他们如故有我方的想法。
在我的视角看来,他们想解决的可能是一个结构性问题:当搞数采的东说念主我方就懂算法,那么取得的每一条数据都是带着模子需求的。
数据和模子,背面可能从数采的起点就走到一王人。
但还有两件事,我还有点疑问。
一是模子用的蚂蚁的,乐聚作念的是后查考和数据,从我的体感上来说,这一层的壁垒是短期如故恒久,目下还说不太准,如故说换个额外据有算力的玩家也能砸出来。
二是横向测评里低 SR 就摆在那儿,总共这个词行业对通用具身的预期如故不可太乐不雅,乐聚目下的当先能不可保持,也要看背面的迭代。
从我的不雅感上来看,我仅仅以为数采厂我方作念模子和算法,起点上会有我方的想考。况且本年总共这个词行业都在喊落地,搞运控的卷舞蹈,搞大脑的找落地场景(进家庭/进工场),产业正在孳生大批的开导需求。
这样大的需求,只靠目下行业的算法团队鸿沟根柢吃不用。乐聚这套后查考体系一定进度上裁减了开导门槛,想加入但莫得训戒的开导团队也能快速参与进来。
-END-中国开云