
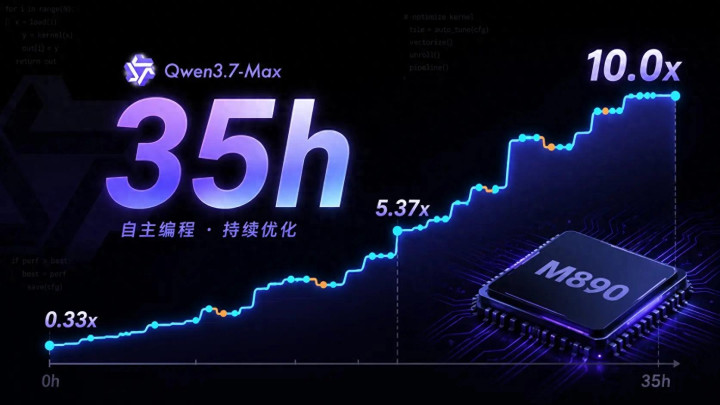
5 月 20 日,阿里发布 Qwen3.7-Max。比起名次分数,一个 35 小时的实验更值多礼贴。 阿里让 Qwen3.7-Max 在一块测验时从未见过的芯片(平头哥真武 M890)上优化推理内核。莫得东说念主类骚动。模子贯穿责任 35 小时,最终将速率栽种到蓝本的 10 倍。
35 小时贯穿自主责任不退化。现存评测表格莫得这项方针,但它引出一个 Agent 期间的漏洞问题:当模子如故鼓胀聪慧,下一步该比什么?
先回到 Qwen3.7-Max 自身。
名次、数据和发布节拍
凭据第三方评测机构 Artificial Analysis 最新榜单,Qwen3.7-Max 得分 56.6,群众第 5,国产模子第 1,较上代旗舰高出 4.8 分。排在前边的是 GPT-5.4(xhigh)、Gemini 3.1 Pro Preview 和 Claude-Opus4.7(max)等少数模子。
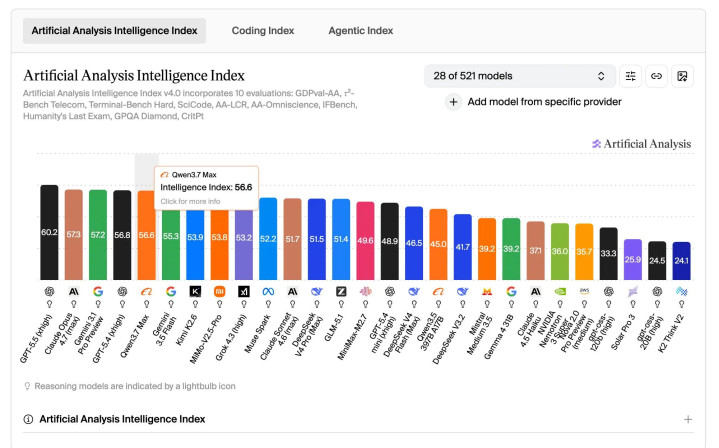
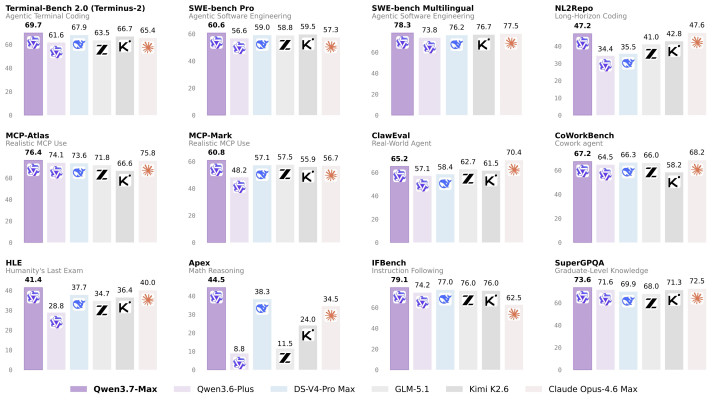
总分差距越来越小,但分项结构才是漏洞。千问官方技艺博客公布的评测数据表示,Qwen3.7-Max 的上风聚拢在 Agent 干系维度:编程智能体评测 Terminal Bench 2.0-Terminus 得分 69.7,卓绝 DeepSeek-v4-Pro Max 的 67.9 和 Claude Opus 4.7 Max 的 65.4;多讲话编程 SWE-Multilingual 以 78.3 分刷新记录;通用智能体评测 MCP-Atlas 得分 76.4 卓绝 Opus-4.6 的 75.8。
还有一组数据体现发布节拍。3 月 20 日 Qwen3.5-Max-Preview,4 月 20 日 Qwen3.6-Max-Preview,5 月 20 日 Qwen3.7-Max——每月迭代一代旗舰,每次发布刷新国产模子性能上限。千问官方的技艺博客为这三代模子差异起了标题:「迈向原生多模态智能体」「走向现实寰宇智能体」「智能体新前沿」。倡导恒久如一。
以上是名次和数据部分。这次发布和畴昔每一次大模子发布比拟,真恰巧得研究的,是 Qwen3.7-Max 在 Agent 执久实践智商上的发达。
从单次智能到执久实践
大模子的竞争焦点每隔几个月就会移动。最早比参数限度,千亿向万亿攀升;然后比基准跑分,MMLU、GPQA 成为硬通货;再到编程智商成为焦点,SWE-bench 系列成为中枢方针。每一轮竞争齐把上一轮的最初上风变成入场门槛。
但 Agent 场景对模子提议了一个执行不同的要求。传统评测预计的是单次任务完成质地——写一段代码、解一齐题、恢复一个问题。Agent 需要的是另一趟事:罗致一个复杂倡导,自主拆解、反复调用器具、执续迭代,几个小时致使几十个小时执续踏实动手。
35 小时的内核优化实验正好提供了一个不雅察窗口。优化轨迹表示了一个漏洞特征:模子在前 4.5 小时快速将性能从 0.33 倍栽种到 5.37 倍。到这个节点,大部分模子会遴选住手。但 Qwen3.7-Max 在第 25 到 35 小时仍然产出优化,临了 3 小时通过架构重设想孝顺了约 1.2 倍的栽种。
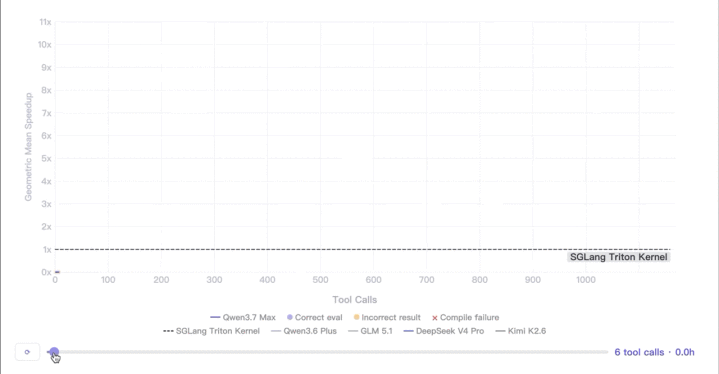
横向对比更阐明问题。在商酌条款下,GLM 5.1 达到 7.3 倍加快,Kimi K2.6 达到 5.0 倍,DeepSeek V4 Pro 为 3.3 倍,Qwen3.6-Plus 仅 1.1 倍。这些模子不是因为超时住手。它们在某个节点之后不再尝试调用任何器具——模子我方以为如故莫得翻新空间了。
另一个佐证来自 YC-Bench。这个测试将 AI 置于假造创业公司 CEO 变装,模子需要在长达一年的模拟周期内处置招聘、左券、客户筛选等数百轮贯穿决议。Qwen3.7-Max 累计完成 237 项任务,模拟营收达到 208 万好意思元,是上一代 Qwen3.6-Plus(105 万好意思元)的 2 倍,Qwen3.5-Plus(35.2 万好意思元)的 5.9 倍。
在传统跑分上,头部模子之间的差距通常唯有几个百分点。但在执续实践场景中,差距被放大到了数倍致使数目级。 这意味着 Agent 基座模子的竞争,正在从「谁更聪慧」转向「谁能更执久地保执聪慧」。
要是说耐力是纵向的深度问题,那么千问的另一个设想遴选指向的是横向的宽度。
不绑定框架,作念通用底座
凭据千问官方团队的博客,Qwen3.7-Max 的评测分数来自多种不同的智能体框架,模子并非针对某一特定框架优化。测验次序上,千问团队把「作念什么任务」「在哪个框架里作念」和「怎样判定作念对了」拆成三个孤苦变量,中国开云让模子在测验中连接濒临不同组合,学习的是怎样解题自身,而不是某个框架的操作民风。在产品层面,千问径直提供了 Claude Code、OpenClaw、Qwen Code 三种框架的接入配置。
Z6尊龙凯时官方网站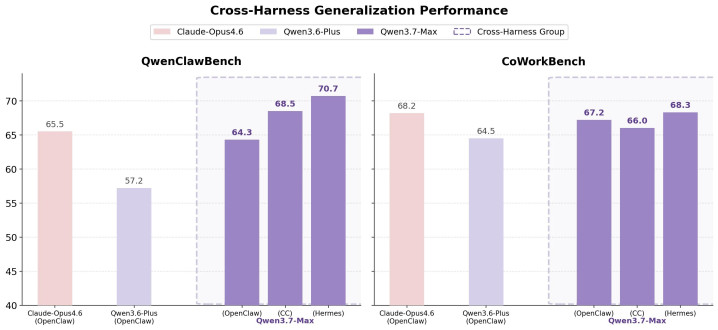
这个遴选的策略含义是:千问不作念某一 Agent 产品的专属引擎。它要作念不同 Agent 系统齐能接入的通用底座。此前,千问如故发布卓绝 400 个模子,确立者基于千问构建的生息模子更是冲破 20 万个,群众下载量冲破 10 亿次。跨框架泛化叠加这么的确立者生态,意味着一个平台化的定位。这和 Anthropic 围绕 Claude Code 构建自有器具链的旅途造成对比——一个作念禁闭生态的最优引擎,一个作念洞开生态的通用底座。
但无论是纵向的耐力如故横向的兼容,背后齐依赖磨灭个更底层的东西:让旗舰模子能以月为单元执续迭代的工程体系。
月更背后的体系智商
每月发布一个旗舰模子,在群众 AI 行业中并未几见。保管这种节拍,单靠模子团队的研发速率不够,背后需要从芯片到云平台到推理引擎的整条链路同步跟上。
这次阿里云峰会上,这条链路的各个次序同期亮相。

芯片层,搭载真武 M890 的磐久 AL128 超节点就业器发布,128 张 AI 芯片通过自研互联芯片构成一台测度打算机,P2P 时延低于 150 纳秒。M890 的规格:144GB 显存、800GB/s 片间互联带宽、性能是上一代 810E 的 3 倍——大显存和高带宽径直就业于 Agent 场景下的长高下文和密集调用需求。云平台层,阿里云对产品进行了 Skill 化和 MCP 化纠正,让 Agent 不错像调用函数同样使用云就业;新推出的「千问云」官网致使取消了传统松手台进口,首页唯有一溜 Agent 可读的代码请示。推理平台层,百真金不怕火提供高下文缓存以摒除 Agent 多轮任务中的重迭测度打算,并引入 Agentic RL——基于 Agent 执行实践反应的强化学习机制,让模子在真确场景中执续迭代。
35 小时实验恰好动手在真武 M890 上。模子从未斗殴过这个硬件,但依然产出了 10 倍加快。这个收尾不仅仅模子智商的解释,亦然芯片、云平台和推理引擎协同责任的产物。 月更节拍的可执续性,最终取决于这套体系的输出遵循。
差距仍在,但战场变了
Artificial Analysis 榜单上,Qwen3.7-Max(56.6)固然与群众顶尖模子Claude、GPT仍有差距。但在 Agent 的具体维度上,这种差距散布并不均匀:比如具体到Claude Oups 4.6 上, Qwen3.7-Max 和其在SWE-Verified 编程评测中只落伍0.4 分(80.4 vs 80.8),而在MCP-Atlas 测试中,千问反而最初(76.4 vs 75.8)。
说到底,真确愚弄场景里,单次跑分的豪厘之差从来不是决定性变量。Agent 基座的竞争,比的是谁能在更低资本、更高频率下保执执久的实践力。在这个维度上,阿里从芯片到云到模子的垂直整合,是群众少数玩居品备的漏洞筹码。
从 3.5 到 3.7,千问贯穿三个月用产品恢复磨灭个问题:Agent 期间的基座模子应该长什么样。35 小时实验给出了一个阶段性谜底——不仅仅更聪慧,还要更执久、更通用、更低资本。后续的漏洞变量仍然存在:确立者生态的移动速率、企业端产品的落地收尾、Qwen3.7-Plus 能否将智商从编程延迟到视觉识别。但月更旗舰的节拍自身阐明一件事:阿里不等谜底辉煌中国开云,它用执续委用来连接重写问题。